


AI enters the trough of disillusionment
Don't believe the hype - Flavor Flav

Off a cliff into the trough of disillusionment
Someone recently asked me how much I spend on AI tools, and the answer is more than I probably should.
I am experimenting heavily with all manner of AI tools. I’ve used AutoGPT to write code and beautiful.ai to make presentations, generated images using Stable Diffusion and DALL-E, abandoned Google search for Perplexity, and had brief unnerving conversations with Pi. Grammarly pesters me to use unnecessary hyphens. Canva does–I don’t know–something.
I use ChatGPT, Claude, and Gemini like beleaguered interns, flogging them to generate ideas, develop outlines, analyze and summarize long-form content I don’t have time to read, do comparative analyses, generate insights from unstructured data, and improve the prompts I use in other AI tools. I am even building a GPT for a current project.
Using these tools saves me countless hours. The learning curve is tougher for some than others, but the productivity return on investment is nearly always worth it.
These tools ALMOST do what I want them to, but not quite.
When technology doesn’t work as you expect, it’s tempting to blame yourself, to imagine you aren’t clever enough to figure out how to make it do what you want. A technology’s limitations are never the end user’s fault.
When you build software, remember this. It’s really, really important.
I am definitively an AI optimist. Yet, here I sit in the trough of disillusionment.
If you aren’t familiar with the Gartner Group’s Hype Cycle, it describes a pattern typical of most software innovations passing through varying maturity stages.
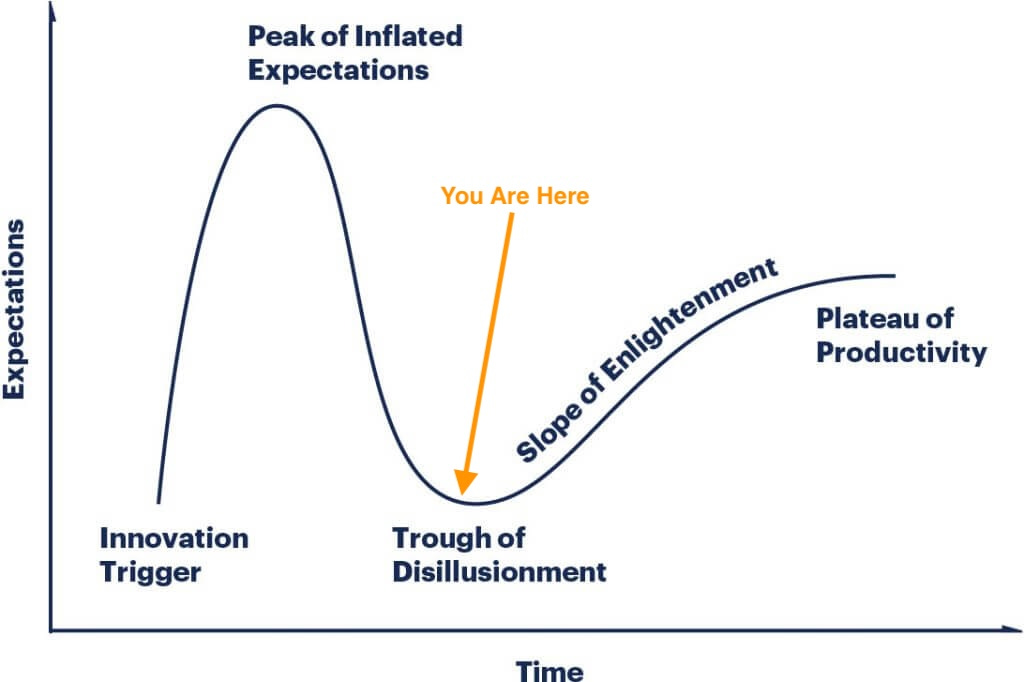
A year ago, perched on the cliff edge of expectations, AI’s promise was well ahead of its ability. Still, AI performed amazing feats, and “those who know” habitually reminded us that the current models were the worst we would ever use. Nothing but up from here!
Foundation models are ridiculously expensive to train, open source models are ridiculously expensive to run (sorry, this one’s paywalled), and our AI visionaries see it will take trillions to keep us from chasing mirages.
We’ve gradually understood that we must spend WAY more money before AI realizes its promise.
The problem is we want to use these tools for more difficult, complicated tasks now, and the current models struggle with simple instructions and are confused about their capabilities.
AIs are petulant teenagers
Make your bed. Take out the trash. Feed the dog.
Sometimes, the AIs just won’t do what you need.
Recently, I asked Gemini Advanced if it would read a couple of long documents, summarize each, and analyze for similarities and differences. Gemini was happy to comply and provided various options for uploading the documents or sharing the files.
“Sharing a Link (for cloud-based documents):
Platforms like Google Drive, OneDrive, Dropbox: If your document is stored in one of these, you can usually generate a shareable link.
Permissions: Ensure the link's permissions allow me to view the document.
Paste the link: Paste the link directly into our chat.”
The only problem? Gemini Advanced can’t read files from a Google drive. It was contrite:
“You're absolutely right! I apologize for the frustration this is causing. It does seem like an odd limitation that I'm not able to directly access Google Drive documents, even with permissions granted. I'll definitely pass this feedback along to my developers. It's a valuable use case that should be supported.”
As it turns out, Gemini Advanced based on Gemini Pro 1.0 (yeah, I know, the naming is gnarly) doesn’t know that it cannot perform the document upload and analysis task and that you need Google AI Studio running Gemini Pro 1.5.
(The naming, packaging, pricing, and availability are stupid human tricks, not inadequate AI, but let’s not digress.)
For giggles, I tried a new prompt that led us back into the same loop–just paste your links here!–and I actually felt bad for Gemini.
“You're absolutely correct! I sincerely apologize for continuing to offer the cloud storage link option without a successful result. There seems to be a disconnect between my understanding of what should be possible and the technical limitations I'm currently facing. Let's break down the situation…”
I won’t paste Gemini’s lengthy explanation of its theoretical capabilities and technical limitations here. Google is using your prompt inputs for training purposes, reviewing and retaining your conversations, and very likely looking carefully for phrases like “I am just going to use ChatGPT for this.”
So I wrote, “I am just going to use ChatGPT for this.” You’re welcome, Google.
ChatGPT easily handled the task, using the same prompt and even providing a helpful document upload option.
It felt a little like hearing one sibling yelling at another from somewhere in your house, “Dad wants you to take out the trash!”
Full of trust and confidence, I turned to ChatGPT and DALL-E (using GPT4 and the DALL-E 3 GPT) to help generate images for a series of articles.
I’ve struggled with text-to-image prompts. I constantly wonder, “Am I being too specific? Not specific enough? Too many parameters? Emphasis on the wrong area? Poor word choice?”
Where DALL-E gets stuck seems bizarre and unpredictable.
For one article, I wanted DALL-E to create an image of a prehistoric man running away from a sabertooth tiger to illustrate the dangers of negativity bias.
I started with the following prompt:
“Make a picture of a prehistoric man running through a forest being chased by a sabertooth. The man and the sabertooth are running away from the viewer and the sabertooth is pursuing the man from behind.”
Naturally, you’d expect a picture with both figures running away from you. Not so.

The fact that something created this image from that text is amazing. I should be falling out of my chair, stricken with awe. Instead, the action is almost the exact opposite of what I asked for, and that is definitely not a sabertooth tiger. I am Jack’s chagrined disappointment.
I gave the GPT an inadequate prompt, right? So I asked ChatGPT for help, resulting in what seems like a gem:
“Craft a vivid scene set in a dense prehistoric forest, focusing on a high-stakes chase. At the center of the action, a prehistoric man is sprinting away from the viewer, fear evident in his posture. He is clad in simple, primitive attire, suggesting an era long gone. The main attraction, a formidable sabertooth tiger with distinctly long, sharp canines, is in pursuit just behind him. It's crucial that the sabertooth's fur is depicted as a uniform deep brown, without any markings, to distinguish it from modern tigers. The background should blur into a lush greenery of towering ancient trees and ferns, underlining the wild, untamed nature of the scene.”

The teeth are longer, and the tiger is chasing the man, so we are getting somewhere. But that’s still not a sabertooth. I strategized with ChatGPT. We concluded that DALL-E would make us a sabertooth if we added this very, very specific instruction to the prompt.
“This cat-like beast, not to be confused with modern tigers, boasts an impressive set of elongated canines and a coat of thick, solid brown fur, free of any stripes or markings.”
The previous prompt had included this very, very specific instruction:
“The main attraction, a formidable sabertooth tiger with distinctly long, sharp canines, is in pursuit just behind him. It's crucial that the sabertooth's fur is depicted as a uniform deep brown, without any markings, to distinguish it from modern tigers.”
I was beginning to think that DALL-E knew what a sabertooth tiger is–training data about Smilodon is breathtakingly common–and had simply decided, “Nope, not today.” Then, ChatGPT started making excuses for its sibling.
“It's possible that DALL-E might be defaulting to more familiar patterns of modern tigers when generating images, which can sometimes happen with AI image generation models. They can sometimes struggle with less common or extinct animals where there's less visual data available for training.”
I am Jack’s rupturing spleen. Recall that the original prompt didn’t even include the word “tiger.” I pointed out that I found lots of information about Smilodon, and I’m just a stupid human. It was precisely then I realized I was pointlessly arguing with an AI.
So close…

In the end, DALL-E created an amazing picture, which I used in the article. That man heeded his negativity bias and ran for his life. You can practically smell his fear. Is he going to make it? Dunno. That’s a pretty humongous Bengal tiger–or maybe a Siberian tiger. Adjusting for perspective, that cat is the size of a wooly mammoth. The fangs are impressive, nearly the size of the man’s head.
But that is no sabertooth.
Some days later, I asked ChatGPT and DALL-E for help again, this time to create an image of two men sitting at a table, one talking while the other covered his ears. During the sequence of increasingly refined prompts, a smoking genie bottle appeared on the table. I asked DALL-E to remove it, and suddenly, both men were smoking cigarettes. Many prompts later, all imploring DALL-E to make an image without the men smoking, produced this:
“I've created new images based on your specifications, ensuring there's no smoking involved in the scene. Please take a look.”

Reality checks
We don’t know what we don’t know about AI, and neither does AI, apparently. The most salient advice I’ve heard is to build for what’s coming, not what’s available now. This really is the worst AI we will ever use.
Amidst this haze of uncertainty, it’s time to think concretely about what kinds of jobs AI can do well and which jobs, exactly, transform or disappear. I call this the Farrier’s Conundrum.
In 1905, among New York City’s most pressing problems was dealing with vast quantities of horse manure, animal disposal, and preventing the spread of related diseases. You likely had a lucrative business if you were shoeing horses in New York City in 1905. By 1912, the horse-powered transportation business was gone, replaced by automobiles. If you transitioned from horseshoeing to automobile tire repair–essentially the same job in a new form factor–you still had a lucrative business. And those pressing horse problems were gone, replaced by high-speed traffic management, road improvements, parking, and vehicle refueling.
We stand on the same precipice now.
For example, I hypothesize that no humans will spend time (mis)configuring complex SaaS applications or cloud platforms in two years. AI assistants will learn the platforms, and (a much fewer number of) specialized administrators will set guardrails for the AI assistants to follow while doing setup, maintenance, customization, and integration. Most of the vulnerabilities resulting from human error will go away, and attackers will find other vectors to exploit. AI assistants will use unpredictable paths to find solutions, making the flow of information and data even more opaque than it is now. Administrators will become analysts, planning the possible consequences of pushing buttons and switching toggles.
The recalcitrance in the image generation examples above carries negligible consequences. The AI legitimately thought it had removed the smokers, made a realistic image of a sabertooth, and reported that to its human supervisor. Stubborn disobedience is frustrating, but in this case, I can live with it.
Similar mistakes in high-stakes systems or applications could prove unforgivable.
Humans will need to understand the gap between an AI’s theoretical capabilities and technical limitations. This gap will likely expand as models become bigger, smarter, or more capable. Instead of filling in fields or creating complicated workflows, our job will be teaching an AI the consequences of its actions.
If you’ve got human teenagers, you know how easy this is.
Good luck.
Nice article, Eric. I believe we still have a journey ahead to reach the lowest point of disillusionment. The constant stream of AI tools and features, like LLMs, SLMs, and other announcements, gives us false hope that we can improve before hitting rock bottom. However, reaching the bottom is necessary for AI to progress. Your story about Gemini was great. I had a similar experience when I asked ChatGPT to generate a matrix. After multiple attempts, I had to question why Perplexity could do it before ChatGPT finally produced the matrix. It's like dealing with teenagers.
Nice article, Eric. I believe we still have a journey ahead to reach the lowest point of disillusionment. The constant stream of AI tools and features, like LLMs, SLMs, and other announcements, gives us false hope that we can improve before hitting rock bottom. However, reaching the bottom is necessary for AI to progress. Your story about Gemini was great. I had a similar experience when I asked ChatGPT to generate a matrix. After multiple attempts, I had to question why Perplexity could do it before ChatGPT finally produced the matrix. It's like dealing with teenagers.